spss19.0的全称为Statistical Product and Service Solutions,中文名统计产品与服务解决方案软件,是一款老牌的数据统计软件。它拥有图表分析、数据管理、输出管理、统计分析等等众多功能,而它的统计分析包括回归分析、数据简化、描述性统计、生存分析、相关分析等等非常多方面的分析。从分析结果来看,它的分析清晰、直接、移动,并且还可以直接读取EXCEL及DBF数据文件,总的来说,它的实用还是非常的强的。软件操作简便,界面非常友好,除了数据录入及部分命令程序等少数输入工作需要键盘键入外,大多数操作可通过鼠标拖曳、点击“菜单”、“按钮”和“对话框”来完成。
PS:本站提供
spss19.0中文版下载,并且还是破解版的,无需授权码,安装包内附有破解补丁,下面还有教程。

安装教程
1、在本站的百度网盘资源上下载好软件安装包,将其解压,然后双击运行“spss19cn”文件夹下面“SPSS_Statistics_19.exe”安装程序,开始安装软件,点击“下一步”,后面的也是一直默认所有的选择,连续点击“下一步”。

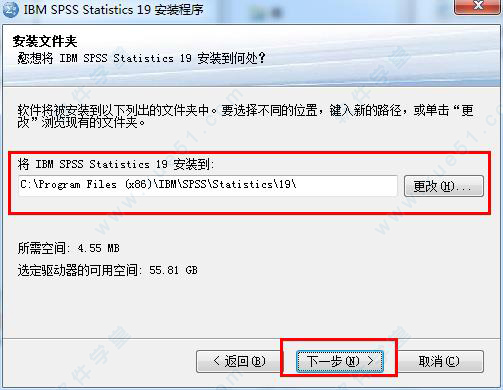
2、切记“安装目录”不能修改。

3、到了最后的安装,点击“安装”。
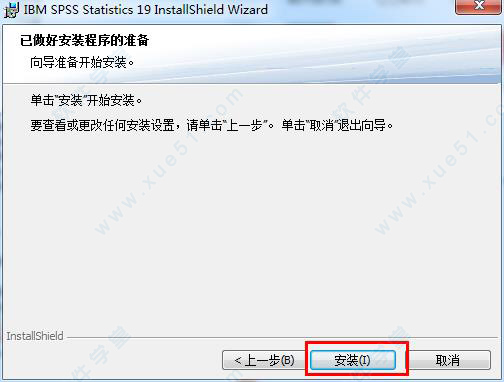
4、安装需要一段时间,请耐心等待。
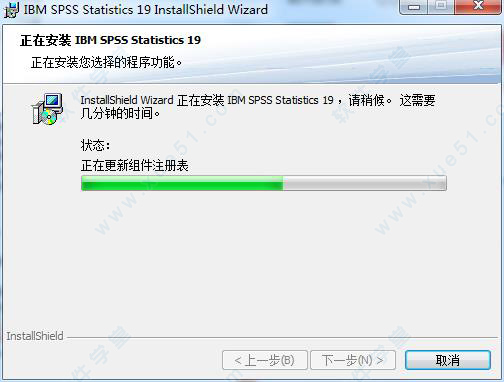
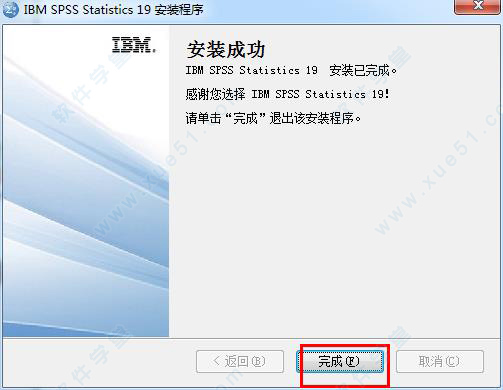
5、安装完成,我们点击“取消”。
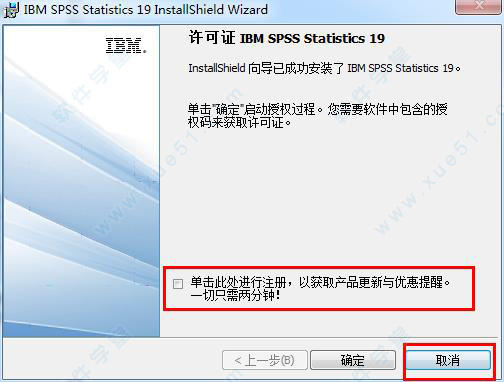
6、接下来安装破解程序,直接点击“下一步”。
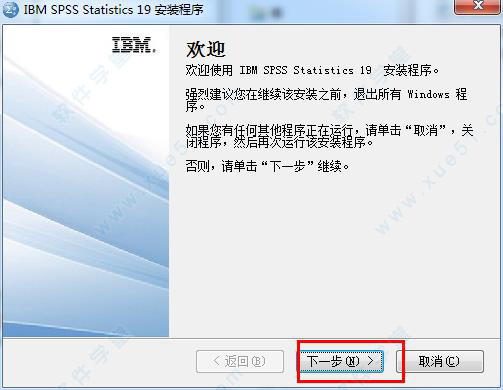
7、安装目录,切记不要,默认就好,默认就是个上面的安装程序在同一目录。
8、安装完成,即破解成功。
9、打开软件,若桌面上没有快捷方式,请在开始菜单栏中打开。

使用说明
一、输入数据我们先来输入变量X的值,请确认一行二列单元格为当前单元格,弃鼠标而用键盘,输入第一个数据0.84,此时界面显示如图A所示:

请注意:在回车之前,你输入的数据在数据栏内显示,而不是在单元格内显示,现在回车,界面如图B所示
首先,当前单元格下移,变成了二行二列单元格,而一行二列单元格的内容则被替换成了0.84;其次,第一行的标号变黑,表明该行已输入了数据;第三,一行一列单元格因为没有输入过数据,显示为“.”,这代表该数据为缺失值。用类似的输入方式,我们将患者的血磷值输入完毕,并将相应的变量GROUP均取值为1,此时数据管理窗口如下所示:

从第12行开始输入健康人的数据,并将相应的GROUP变量取值为2。最终该数据集应该有24条记录。
二、保存数据选择菜单File==>Save,由于该数据从来没有被保存过,所以弹出Save as对话框如下:
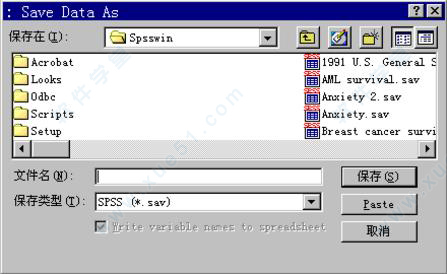
单击保存类型列表框,可以看到软件所支持的各种数据类型,有DBF、FoxPro、EXCEL、ACCESS等,这里我们仍然将其存为自己的数据格式(*.sav文件)。在文件名框内键入Li1_1并回车,可以看到数据管理窗口左上角由Untitled变为了现在的变量名Li1_1。
为什么这里的对话框会出现汉字?是这样的,需要从编程的角度来解释:该软件在 弹出该对话框时会调用Windows系统的公用函数,由于我们用的是中文Windows系统,所以调用出来的就是中文。
三、分析数据录入完数据后,你可以先进行基础的数据统计--描述性统计。然后根据你的数据结果再看是否需要相关回归或者其他分析。这款软件里面的描述统计主要在analyze——descriptive里面,其中有描述统计、频数统计、交叉分析。
描述性统计分析是统计分析的第一步,先选择analyze,你就能看到descriptive,然后鼠标再选Descriptive 菜单中,最常用的是列在最前面的四个过程:Frequencies过程的特色是产生频数表;Descriptives过程则进行一般性的统计描述;Explore过程用于对数据概况不清时的探索性分析;Crosstabs过程则完成计数资料和等级资料的统计描述和一般的统计检验
先选择analyze,---再选descriptive
打开任意的分析窗口后,你把想分析的数据选入,可以一起按鼠标左键选中按中间按钮加入,然后选择单击后弹出Statistics对话框,用于定义需要计算的其他描述统计量。你可以分析均数(Mean)、中位数(Median)、众数(Mode)、总和(Sum)等等。 然后还可以点Charts对话框,选择直方图、饼图等来绘图。都确定好后,选择单击Continue钮 ,然后选择OK。就可以了。直接就会有输出结果。
你可以先看看描述性统计的结果,有没有什么缺失值或者不符合实际的数据出现。要是有,你需要纠正数据,再用描述统计进行分析。
四、直接定义新变量
大多数情况下我们需要从头定义变量,在SPSS 10.0中,定义变量的操作界面和FoxPro等数据库非常相似,只需单击左下方的Variable View标签就可以切换到变量定义界面开始定义新变量。如Li1_1.sav的变量定义如下所示:

以变量x为例:变量名为x,类型为Numeric,宽度为4,小数位数2位(因小数点还要占一位,故整数位只有一位),变量标签位为“血磷值”。右侧在图中未能看到的依次为Values,用于定义具体变量值的标签;Missing,用于定义变量缺失值;Colomns,定义显示列宽;Align,定义显示对齐方式;Measure,定义变量类型是连续、有序分类还是无序分类。
使用该窗口,我们可以一次定义许多新变量,不会象老版本那样一个一个的定义了。
由于是英文软件,变量名采用中文会有潜在的冲突(100%的兼容性是不存在的,典型的例子就是微软公司的产品)。
对于喜欢搞点花样的用户,这里有必要介绍一下这款软件中标签和缺失值的定义方法:
标签 和老版本不同,现在变量标签和变量值标签被分开设置,变量标签就在Label框中直接输入,变量值标签则在它右侧的Value框定义。以group为例,单击Value框右半部的省略号,会弹出变量值标签对话框如下:

上部的两个文本框分别为变量值输入框和变量值标签输入框,分别在其中输入“1”和“克山病患者”,此时下方的Add钮变黑,单击它,该变量值标签就会被加入下方的标签框内。与此类似定义变量值“2”为“健康人”,最后按OK,变量值标签就设置完成。此时你做任何分析,在结果中都有相应的标签出现。如果你现在就想看效果,切换回Data View界面,然后选择菜单View==>Value Labels,怎么样,看到了吗?
缺失值 单击missing框右侧的省略号,会弹出缺失值对话框如下:
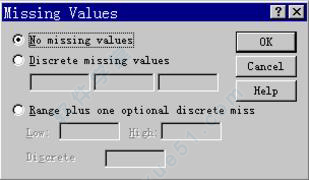
界面上有一列三个单选钮,默认值为最上方的“无缺失值”;第二项为“不连续缺失值保疃嗫梢远ㄒ?个值;最后一项为“缺失值范围加可选的一个缺失值”,文如其意,不用我多解释了吧。
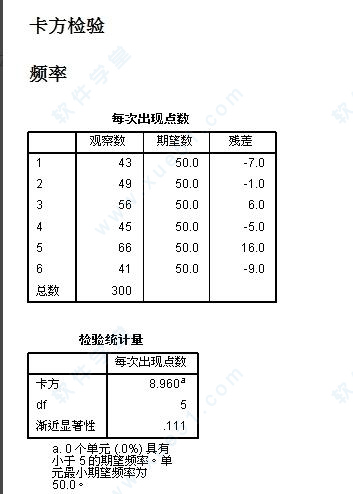
卡方检验
1、首先,打开或者新建立一组数据。
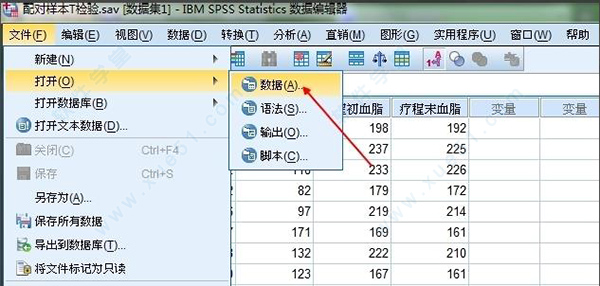
2、这里是打开了一组案例分析中的数据进行分析。
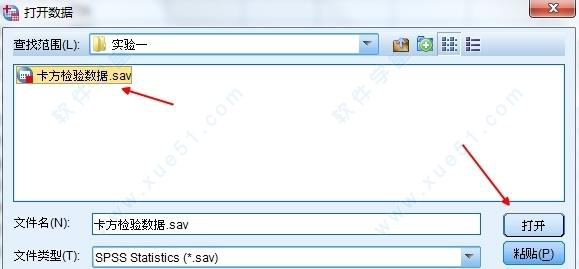
3、找到非参数检验->就对话框->卡方检验,将其单击单击打开。

4、下面是卡方检验的参数设置窗口。将左边的原变量选入到检验变量列表中。
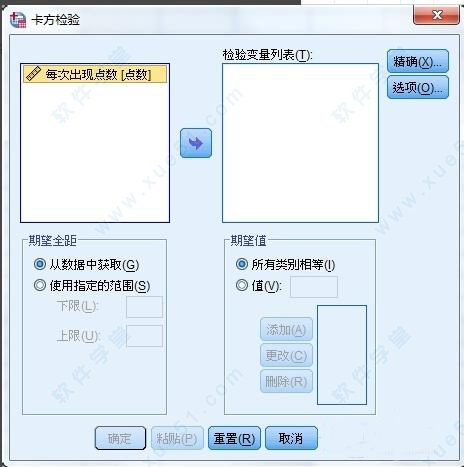
5、打开精确,里面的值默认如下图所示,一般不需要更改。

6、打开选项窗口,将描述性复选框按钮进行勾选。
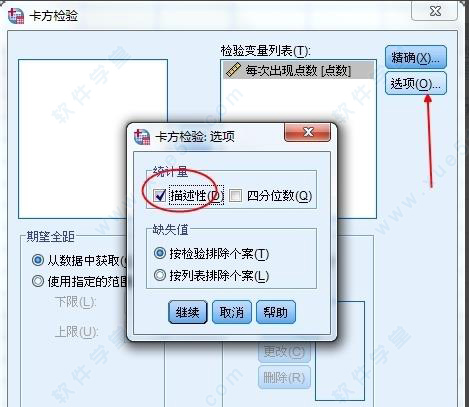
7、再将期望单选和期望值选择好。全部参数设定好之后单击确定获得检验分析结果。

8、检验分析结果如下图所示:
主要功能介绍
一、数据管理在10版以后,该软件的每个新增版本都会对数据管理功能作一些改进,以使用户的使用更为方便。13版中的改进可能主要有以下几个方面:
1、超长变量名:在12版中,变量名已经最多可以为64个字符长度,13版中可能还要大大放宽这一限制,以达到对当今各种复杂数据仓库更好的兼容性。
2、改进的Autorecode过程:该过程将可以使用自动编码模版,从而用户可以按自定义的顺序,而不是默认的ASCII码顺序进行变量值的重编码。另外,Autorecode过程将可以同时对多个变量进行重编码,以提高分析效率。
3、改进的日期/时间函数:本次的改进将集中在使得两个日期/时间差值的计算,以及对日期变量值的增减更为容易上。
二、结果报告在16版中,该软件推出了全新的常规图功能,报表功能也达到了比较完善的地步。13版将针对使用中出现的一些问题,以及用户的需求对图表功能作进一步的改善。
1、统计图:在经过一年的使用后,新的常规图操作界面已基本完善,本次的改进除使得操作更为便捷外,还突出了两个重点。首先在常规图中引入更多的交互图功能,如图组(Paneled charts),带误差线的分类图形如误差线条图和线图,三维效果的简单、堆积和分段饼图等。其次是引入几种新的图形,已知的有人口金字塔和点密度图两种。
2、统计表:几乎全部过程的输出都将会弃用文本,改为更美观的枢轴表。而且枢轴表的表现和易用性会得到进一步的提高,并加入了一些新的功能,如可以对统计量进行排序、在表格中合并/省略若干小类的输出等。此外,枢轴表将可以被直接导出到PowerPoint中,这些无疑都方便了用户的使用。
三、统计建模Complex Samples是12版中新增的模块,用于实现复杂抽样的设计方案,以及对相应的数据进行描述。但当时并未提供统计建模功能。在13版中,这将会有很大的改观。一般线形模型将会被完整地引入复杂抽样模块中,以实现对复杂抽样研究中各种连续性变量的建模预测功能,例如对市场调研中的客户满意度数据进行建模。对于分类数据,Logistic回归则将会被系统的引入。这样,对于一个任意复杂的抽样研究,如多阶段分层整群抽样,或者更复杂的PPS抽样,研究者都可以在该模块中轻松的实现从抽样设计、统计描述到复杂统计建模以发现影响因素的整个分析过程,方差分析模型、线形回归模型、Logistic回归模型等复杂的统计模型都可以加以使用,而操作方式将会和完全随机抽样数据的分析操作没有什么差别。可以预见,该模块的推出将会大大促进国内对复杂抽样时统计推断模型的正确应用。
四、模块Classification Tree模块基于数据挖掘中发展起来的树结构模型对分类变量或连续变量进行预测,可以方便、快速的对样本进行细分,而不需要用户有太多的统计专业知识。在市场细分和数据挖掘中有较广泛的应用。已知该模块提供了CHAID、Exhaustive CHAID和C&RT三种算法,在AnswerTree中提供的QUEST算法尚不能肯定是否会被纳入。
为了方便新老用户的使用,Tree模块在操作方式上不再使用AnswerTree中的向导方式,而是这款软件近两年开始采用的交互式选项卡对话框。但是,整个选项卡界面的内容实际上是和原先的向导基本一致的,另外,模型的结果输出仍然是AnswerTree中标准的树形图,这使得AnswerTree的老用户基本上不需要专门的学习就能够懂得如何使用该模块。
软件特色
1、操作简便
界面非常友好,除了数据录入及部分命令程序等少数输入工作需要键盘键入外,大多数操作可通过鼠标拖曳、点击“菜单”、“按钮”和“对话框”来完成。
2、编程方便
具有第四代语言的特点,告诉系统要做什么,无需告诉怎样做。只要了解统计分析的原理,无需通晓统计方法的各种算法,即可得到需要的统计分析结果。对于常见的统计方法,这款软件的命令语句、子命令及选择项的选择绝大部分由“对话框”的操作完成。因此,用户无需花大量时间记忆大量的命令、过程、选择项。
3、功能强大
具有完整的数据输入、编辑、统计分析、报表、图形制作等功能。自带11种类型136个函数。该软件提供了从简单的统计描述到复杂的多因素统计分析方法,比如数据的探索性分析、统计描述、列联表分析、二维相关、秩相关、偏相关、方差分析、非参数检验、多元回归、生存分析、协方差分析、判别分析、因子分析、聚类分析、非线性回归、Logistic回归等。
4、数据接口
能够读取及输出多种格式的文件。比如由dBASE、FoxBASE、FoxPRO产生的*.dbf文件,
文本编辑器软件生成的ASCⅡ数据文件,Excel的*.xls文件等均可转换成可供分析的数据文件。
5、模块组合
软件分为若干功能模块。用户可以根据自己的分析需要和计算机的实际配置情况灵活选择。
6、针对性强
该软件针对初学者、熟练者及精通者都比较适用。并且很多群体只需要掌握简单的操作分析,大多青睐于这款软件,像薛薇的《基于SPSS的数据分析》一书也较适用于初学者。而那些熟练或精通者也较喜欢这款软件,因为他们可以通过编程来实现更强大的功能。







0条评论